March 12, 2025
Directed Acyclic Graphs (DAGs) for Data Availability

Data remains one of the biggest hurdles in building robust, scalable decentralized networks and applications. When attempting to increase throughput in blockchains, however, this has almost always come at the cost of decentralization and security. So is there a way to get speed without sacrificing the core principles of decentralization? The short answer is yes, and it lies in the core architecture of Hyve’s architecture: Directed Acyclic Graph (DAG)., By employing a DAG architecture, Hyve allows for multiple operations to happen concurrently, resulting in quick and verifiable data, writing at massive volumes of at least 1 gigabytes per second. Although DAGs can seem daunting, this article will demystify the concept and explain how HyveDA leverages it to benefit both developers and end-users.
The Basics
It seems prudent to begin with the burning question, “What IS a Directed Acyclic Graph?”. A DAG is essentially a network of points connected by a path that goes only one direction. Each point can be connected to multiple other points, rather than just one other points like in a blockchain. “Directed” means each connection has a defined arrow, and “acyclic” tells us these arrows never form a loop. In other words, you can follow the arrows from one node to the next, but you’ll never find yourself back where you started.
To visualize this, picture a tree trunk branching upward. Each new branch splits off in a particular direction, but none of them ever reconnect, meaning there’s no chance of looping back down to the trunk. That’s the basic idea behind a DAG: every path moves forward, never circling around.
To fully understand DAGs, let’s compare them to blockchains. Blockchains are linear: Each block references the previous block and only a single block can be added at a time. While this functions sufficiently in many use cases, particularly to avoid issues with processing conflicting transactions in parallel, it is not the most efficient architecture for data availability. Where blockchains like Ethereum deal with state-altering transactions, data availability is only concerned with raw data. Because plain data doesn’t carry the same risk of conflicting states that financial transactions do, a linear, single-file approach can become a bottleneck.
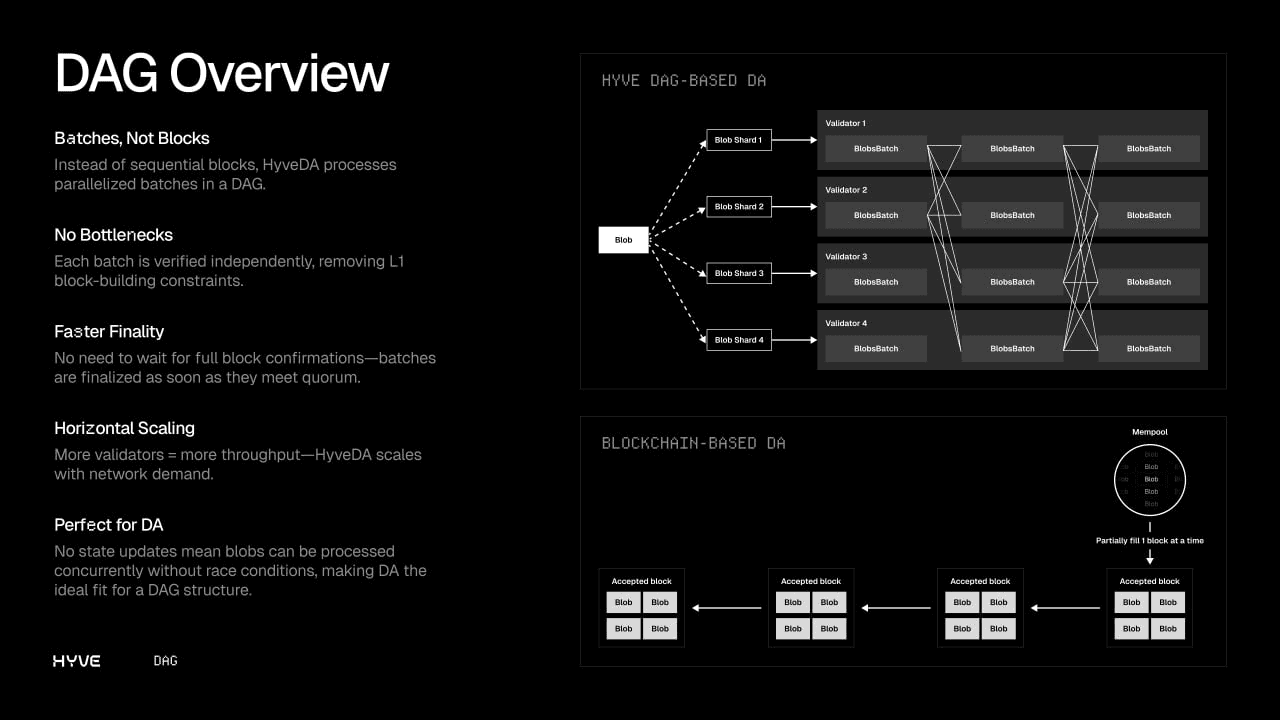
In a DAG, on the other hand, the single sequential lane of blocks expands into multiple lanes. Each block can link to multiple previous blocks and multiple later blocks. Instead of referencing only one previous block, each new block can link to multiple predecessors (and successors) at once, all connected by cryptographic proofs that secure the data’s integrity. This allows multiple blocks to be proposed and processed in parallel without risking the formation of loops. Although the structure is more flexible, you never stray from the overall “trunk,” ensuring both consistency and high throughput for data availability.
At Hyve, the DAG is the backbone of our architecture. It provides a verifiable overview of processed data without depending on any single authority. Meanwhile, multiple data sets can be proposed and accepted in parallel, giving us a secure, decentralized system that also scales horizontally to handle high volumes of data.
Benefits of a DAG
DAGs bring a host of benefits that solve some of the biggest challenges blockchains face:
Parallel Processing
In contrast to blockchains, which add one block at a time in a sequential manner, DAGs enable multiple data entries to be processed simultaneously. This parallelization means that as network activity increases, the system can handle more data without becoming congested. This becomes incredibly valuable for protocols and platforms that see spikes in user activity, such as DeFi, AI, and Gaming. Without a single bottleneck, these spikes do not lead to congestion.
Enhanced Scalability
With a DAG, the network's capacity grows with the number of validators. Rather than facing bottlenecks as more validators join, the system adapts dynamically. More participants lead to more validation paths, resulting in faster processing speeds.
Robustness and Fault Tolerance
The structure of a DAG naturally provides redundancy. With multiple pathways for transaction verification, the network remains resilient even if some nodes fail or are compromised, ensuring continuous and reliable operation.
How Hyve’s DAG works exactly
Hyve has integrated the concept of a DAG in such a way that it can exist as a standalone Data Availability layer. The goal is to create a byzantine fault tolerant and canonical data availability layer, but without a state that determines finality or ordering. Instead of having consensus, Hyve integrates with other consensus layers, but more on that in a future article.
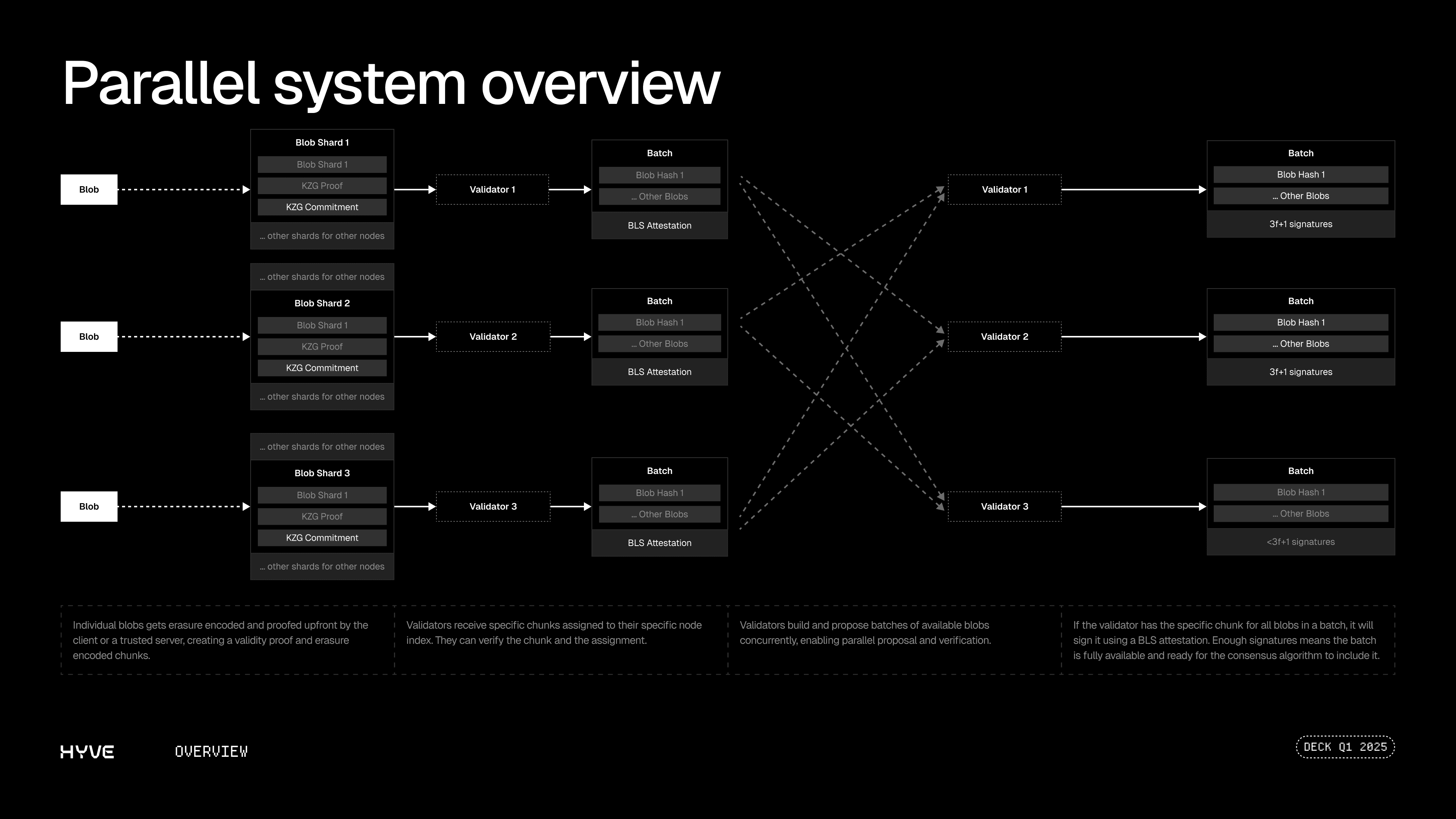
In Hyve’s DAG, the transactions are the blobs that a user submits. This lifecycle kicks off by the user erasure coding and proving its blob. The resulting chunks are submitted to different operators in the network. Each operator is responsible for a specific chunk and therefore will hold its own chunks only. When an operator has a decent amount of these, it will propose the blob identifiers of these chunks in a batch. Operators validate the proposed batches and accept them. Future batches can then be proposed as children of these accepted batches.
Since we employ the DAG architecture, this is not something that only one operator does. Instead, all operators can propose and vote on batches in parallel. This allows for a lot of blobs to be processed in parallel, instead of being queued by a single proposed block.
Recap
As we can now see, employing a DAG is the largest benefactor to the impressive throughput and scalability HyveDA is able to achieve. By maximizing the speed and efficiency of data and reducing the bottlenecks found in linear blockchains, HyveDA opens the door to blockchain innovation. AI, DeFI, DePin, GameFI, they are all limited by how fast can data move on a blockchain, and how much can it be trusted? By eliminating that concern, these protocols are free to build, released from the chains of slow and clunky data. Adoption happens when blockchain technology can offer the tools that people want and need while matching, or exceeding, the user experience they are already accustomed to.